
芯东西3月13日报道,被业界誉为“芯片设计国际奥林匹克会议”的国际固态电路大会(ISSCC 2023)近日在美国旧金山举行。今年恰逢ISSCC 70周年大庆,这也是自2020年疫情以来首次全线下模式召开的芯片设计领域的国际盛会,来自全球产学界的数千名领域专家齐聚。
ISSCC始于1953年,是全球学术界和工业界公认的集成电路设计领域最高级别会议,通常是各个时期国际上最顶尖固态电路技术最先发表之地。世界上第一个集成模拟放大器芯片、第一个8位微处理器芯片、第一个32位微处理器芯片、第一个1Gb内存DRAM芯片、第一个多核处理器芯片等里程碑式发明均是在ISSCC首次披露。
在2023年ISSCC共录用的198篇同行评审论文中,中国大陆及港澳地区贡献了59篇,排名世界第一,中国台湾地区贡献了23篇。其中清华大学为第一署名单位的论文共入围13篇,北京大学有6篇论文获收录。
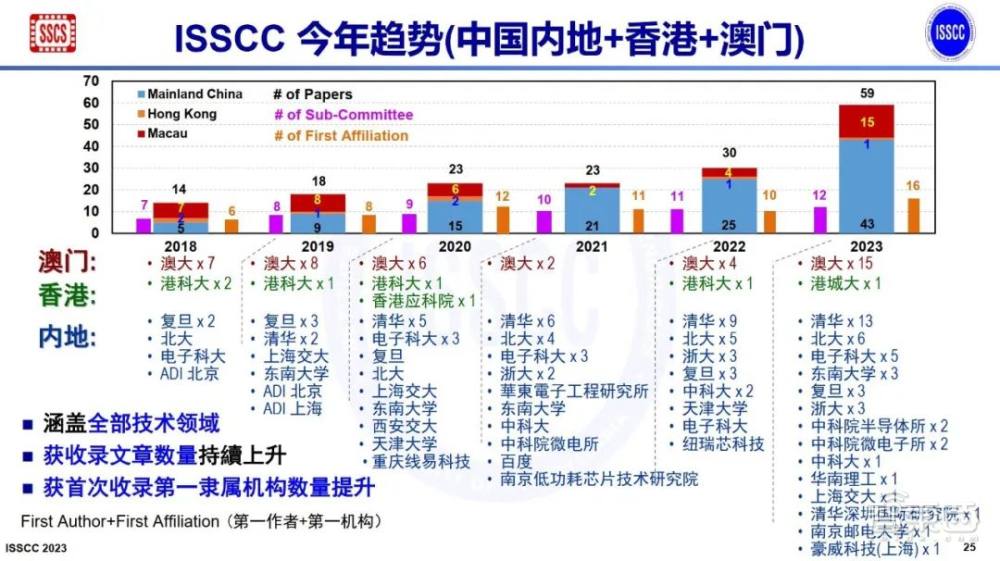
本届大会上,北京大学集成电路学院/集成电路高精尖创新中心共有6篇高水平论文入选,研究成果覆盖了存算一体AI芯片、模拟与数字混合芯片、时钟芯片、高速互连芯片等领域,涉及ISSCC大会全部12大领域中的4个领域,论文数在国际高校里排名第5,在国际高校和企业里排名第9,这也是北京大学连续4年在ISSCC大会上发表论文。
清华大学电子工程系共有5篇高水平论文入选,研究成果涵盖了近似数字存内计算电路、面向自动驾驶等领域的3D点云处理器、超低功耗模数转换电路、宽带太赫兹倍频芯片、面向神经接口的超低功耗高吞吐率发射机设计。
本文将这11篇论文分为存算一体/近存计算芯片、3D点云处理器芯片、面向物联网IoT应用的芯片、模数转换芯片、通信芯片五大类。
面向边缘AI场景,针对传统存内计算芯片冗余数据处理产生功耗浪费的问题,课题组提出了基于差值求和计算方式的模拟存内计算拓扑,利用边缘AI场景中输入特征值逐渐且偶然变化的特点,自适应的消除冗余数据处理产生的功耗,显著提升了神经网络计算能效。该创新通过处理输入变化量而非输入绝对值的方式,最大限度消除了不变数据处理所浪费的功耗,提升了计算效率。
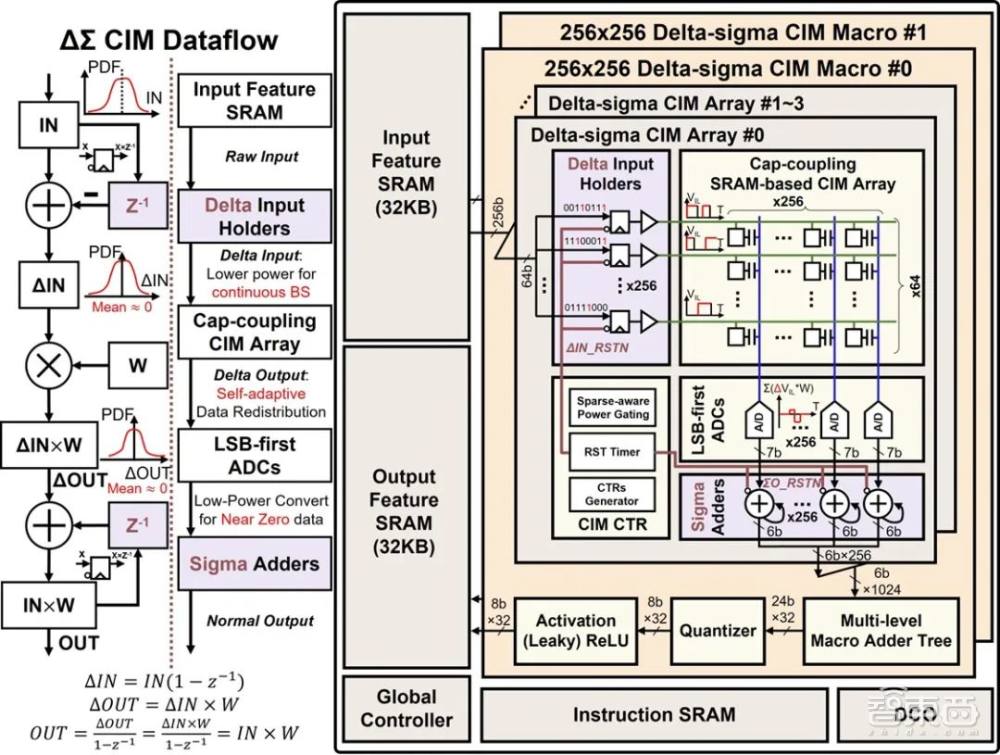
▲(a)差值求和存内计算芯片数据流与架构图(图源:北京大学集成电路学院)
北京大学黄如院士-叶乐教授团队,提出了差值输入技术和差值矩阵乘法技术,通过将输入特征值由绝对量变为变化量的方式,降低了存内计算阵列计算功耗,并实现自适应的输出分布集中;此外,还提出了低位优先模数转换器,通过减少较小数据模数转化次数的方式,在不损失计算精度的情况下,显著降低了模拟存内计算中的模数转换功耗。
基于上述创新技术,该课题组研制了差值求和模拟存内计算芯片,在8-bit输入/8-bit权重/全精度输出的情况下,实现了21.38TOPS/W的峰值能效,1.44TOPS/mm2的峰值单位面积算力;在综合评估指标(=能量效率×面积效率)下,达到了26.72TOPS/W×TOPS/mm2,是世界最好的存内计算芯片的1.25倍。
该创新具有高能效、高算力、高通用性三大特性,可应用于边缘端AI计算场景,如图像识别、语音识别、安防监控等。该创新有望与图像传感器相结合,实现针对边缘端AI的感存算一体高效智能处理。

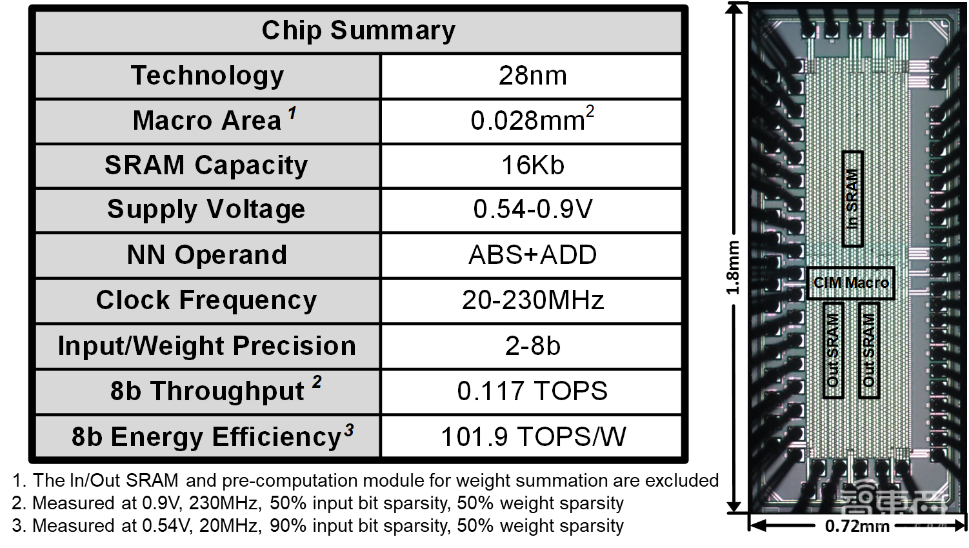
数字存内计算技术相比于模拟存内计算具有高精度、易集成的特点,但其能量效率和面积效率受数字乘累加电路限制难以进一步提升。针对该关键问题,研究团队设计并流片验证了一款基于SRAM的高能效近似数字存内计算芯片。
该芯片采用加法网络近似传统卷积网络,通过L1距离代替乘法运算,大幅削减了数字电路开销,同时采用预计算重塑数据流,将绝对值计算进一步简化为比较操作。此外,设计的高密度动态逻辑比较器通过电路级的可约束近似计算进一步提升能效和面积效率。
基于以上创新点设计的存内计算芯片采用28nm工艺制造,峰值8比特计算能量效率达到102TOPS/W,相比于相同工艺下数字存内计算工作能效提升3倍以上,展示了近似数字存内计算电路的性能优势。
相比2D视觉信息,3D点云数据可以提供丰富的几何、形状和深度信息,使得深度3D点云模型在自动驾驶、智能机器人等领域得到广泛应用。
然而3D点云数据具备稀疏、非规则的分布特性,带来随机数据存取访问、2D/3D多样稀疏卷积计算、非均衡计算核心调度等硬件难题,限制其面向实际应用落地。
为提升点云模型的硬件运行效率,研究团队设计并发布了2D/3D融合的稀疏点云加速器芯片。团队基于分块存储管理机制实现无序稀疏数据的连续、高效传输,设计2D/3D多稀疏度可重构卷积计算电路实现4类稀疏卷积的高效支持,提出多核心混合调度优化策略解决稀疏计算存在的负载不均衡、数据复用效率低的问题。
该芯片是首款支持大规模化点云模型端到端运行的智能芯片,在台积电28nm工艺下成功流片,峰值处理能效达到4.68TOPS/W,相比2022年文献中的相关工作能效提升2倍以上。
同时,团队将该芯片与激光雷达集成实现了可演示实时系统,并在ISSCC Demo环节中进行展出,显示出其对点云模型强大的实时推理能力。

该工作面向物联网传感器应用,针对不断上升的高速高精度电容数字转换器需求,实现了一款高性能电容传感器,解决了传统高精度电容传感器的架构不利于高速转换的问题,突破了传统电容采样过程中采样热噪声造成的性能瓶颈。
针对以上问题,北京大学黄如院士-叶乐教授团队,从架构和电路两个层面提出解决方案。
架构层面,本工作创新性地将流水线型逐次逼近型寄存器转换架构引入电容传感器领域,突破传统架构面临的转换精度、能效和转换速度之间的折衷关系。
电路层面,该工作首次提出了可应用于电容传感中的kT/C采样噪声消除技术,解决了小电容传感中的精度上限问题,突破了采样热噪声的精度瓶颈。
此外,该工作还首次提出了基于不完全建立的相关电平抬升技术,缩短了传统增益提升技术的粗放大阶段,减少了额外功耗,并将等效开环增益大幅提升,提供了极高的增益稳定性,提高了级间放大器的能量效率和精度。
基于上述架构和电路层面的创新,课题组研制了一款基于22nm CMOS工艺的紧凑型高能效电容传感器芯片。该电路在22nm工艺下实现了对0-5.16pF电容值测量,精度达37.12aF,在所有高精度(1fFrms噪声水平)电容传感器中具有最高能效(7.9fJ/conv.-step),且达到了71.3dB的信噪比,相较现有工作将能效提升了1倍。
该电路具有高能效、高精度、小面积、高转换速度等特点,可广泛应用于面向电容传感的各类物联网传感器和前端应用中,并且为电容传感芯片的小型化提供了全新的解决方案。

▲(a)电容传感器架构图和创新技术(b)电容传感器芯片显微照片和性能对比图(图源:北京大学集成电路学院)
该工作面向智能物联网AIoT芯片应用,针对需要周期唤醒的AIoT芯片,设计并实现了一款超低功耗晶体振荡器电路,并实现了综合条件下国际领先的低功耗与计时精度。
北京大学黄如院士-叶乐教授团队提出了基于Gm-C的电流注入时间控制电路与振幅检测电路:该技术创新性地利用了Gm-C这一基础模拟电路模块,解决了电荷注入式晶体振荡器的电流注入时间与大小控制的挑战,使得基于此技术的32kHz实时时钟(RTC)电路能够在实现高精度计时的同时,在应用环境温度范围内仅消耗最多不到2nW的功耗;与此同时,由于模拟电路功耗主要取决于其偏置电流,在内置电流源的情况下,该电路较已发表的同类工作相比,实现了功耗对温度最低的敏感性。

基于上述创新理念与技术,课题组研制了一款基于22nm CMOS工艺的超低功耗32kHz晶体振荡器芯片。该电路在使用ECS-2X6X音叉型32kHz晶体下,在25˚C室温下的平均功耗仅为0.954nW,取得了已发表过的基于32kHz电流注入晶体振荡器中功耗最低的世界纪录。其在80˚C下的功耗仅为1.90nW,为低功耗晶体振荡器中的世界纪录。
该晶体振荡器在长时工作下表现出了低至6ppb的Allan误差(Allan Deviation),取得了单电源晶体振荡器电路的长时稳定性世界纪录。该电路可广泛应用于面向环境应用的IoT芯片中,作为其中低功耗高精度实时时钟模块的核心。

面向语音识别、智慧医疗等多种物联网应用,针对其对中等带宽信号实现高精度、高能效采集的需求,本工作实现了一种在性能上国际领先且易于驱动和系统集成的增量型缩放式模数转换器,相比于其他同类型的缩放式模数转换器设计取得了最高的带宽和最低的驱动需求。
本工作在缩放式模数转换器的架构和电路方面提出了新的设计方法:在架构方面,首次采用噪声整形逐次逼近型量化器进行缩放式模数转换器中的细量化,并提出了一次采样多次量化的量化方法,大幅降低了对采样电路的要求,提升了系统的带宽;在电路方面,提出了一种新型的环路滤波器电路设计方法,该方法仅需要一个动态缓冲器即可实现高阶、高鲁棒性的环路滤波器,显著降低了系统硬件开销和功耗。

基于上述创新技术,课题组研制了一款基于28nm CMOS工艺的增量型缩放式模数转换器芯片。
该款芯片一次模数转换仅需要8次采样,在低频2.5kHz和中频20kHz的输入信号下分别达到了92.5dB和92.2dB的信噪失线μW,在同类的缩放式模数转换器中具有最高的输入带宽(150kHz),且易于驱动,单次转换所需的输入驱动开销最小,整个系统达到了国际领先的模数转换器能效水平(182.2dB FoM)。该电路可广泛应用于多种物联网应用场景,并且为如缩放式模数转换器的多步模数转换器提供了新的实现和量化方法。
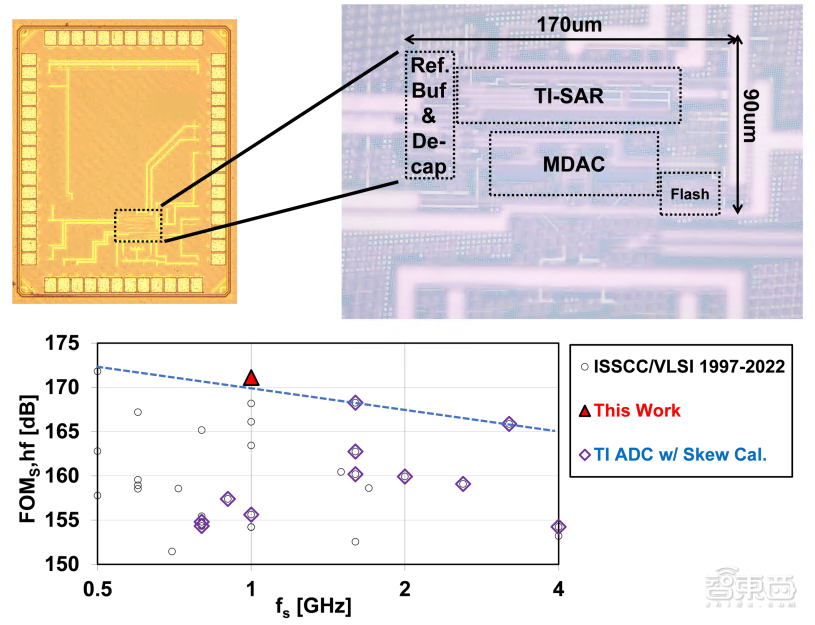
下一代无线通信系统(如WiFi-7)向着更高带宽与更高阶调制进展,对高速(1GS/s)中高精度(12比特)模数转换器(ADC)有着迫切需求,且ADC功耗往往成为系统的功耗瓶颈。
针对高速高精度ADC的低功耗设计挑战,研究团队采用了流水线与时间交织融合的架构,在避免了时间交织复杂校准的同时大幅降低了功耗;针对高速余差放大器设计问题,通过分裂电容的方式解决了低电源电压下高速环形放大器的PVT稳定性问题。
12比特ADC采用28nm工艺实现,在1GS/s采样率下包含基准缓冲器的总功耗仅为10mW,并达到63dB的SNDR,是目前相同指标下功耗最低的ADC。
不断增长的通信需求持续推动有线通信链路向更高的数据速率演进,目前超高速有线收发机的数据速率已达到100+Gb/s量级。为了提高频谱利用率,四电平脉冲幅度调制(PAM-4)在超高速链路中被广泛采用。然而PAM-4调制方式面临眼宽、眼高减小的挑战。
北京大学盖伟新教授团队从电路设计和均衡机制方面入手,提出了可编程宽度的脉冲发生器,依靠脉冲宽度调节驱动器增益,从而实现最快信号翻转速度,减小信号边沿在码元宽度中占据的比例,改善眼宽;提出了基于码型的预加重均衡机制,通过检测电路对待发送的信号码型实时监测,在特定信号处以注入电流的方式加强信号,消除码间干扰的同时避免输出摆幅衰减。
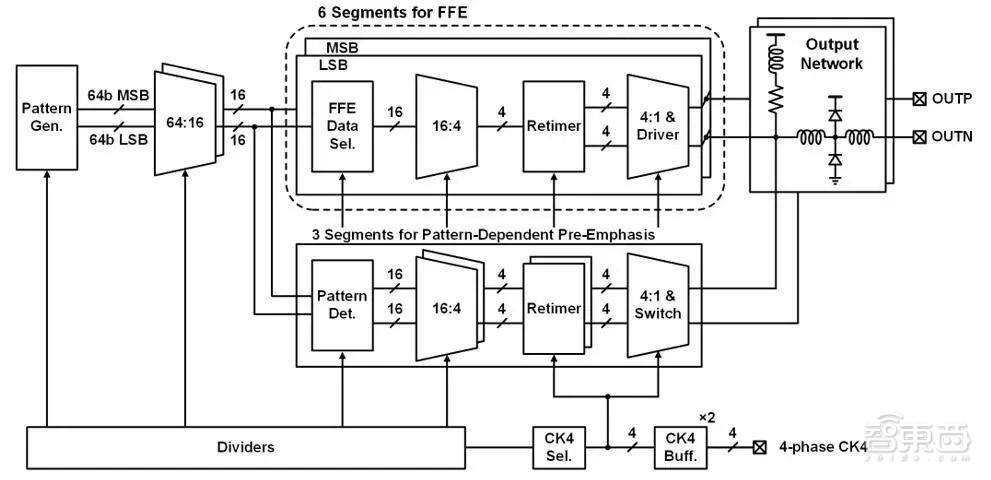
基于28nm CMOS工艺的超高速有线发送机芯片,并对芯片进行了性能测试与汇报。该发送机芯片实现了高达128Gb/s PAM-4的数据速率,并且取得了1.4pJ/b的能量效率;提出的可编程宽度脉冲发生器实现了13%的眼宽增长,且没有额外的功耗代价;相比传统前馈均衡,基于码型的预加重均衡机制使得眼图张开面积提高了约25%。该电路可广泛应用于数据中心、高性能计算等高通信需求的场景,为其提供高速率、高可靠的数据传输。

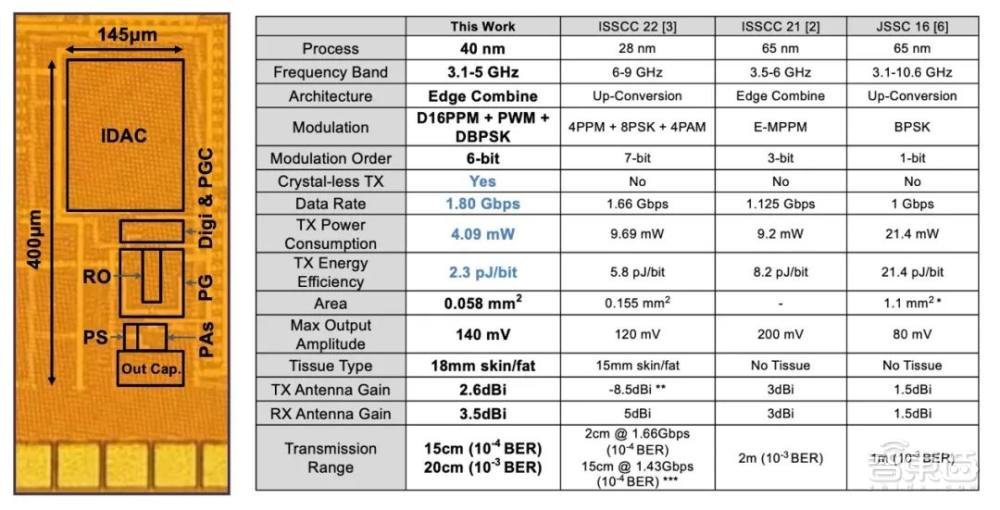
近年来脑机接口前沿领域涌现了一批千通道以上的高密度电极,与这些电极搭配的无线传输技术需要满足高速率(1Gbps),低功耗(10mW),小体积和经皮传输四大条件。
针对这些挑战,研究团队首先设计了D16PPM-PWM-DBPSK的IR-UWB混合调制方式,让单个IR-UWB脉冲可以调制6bit信息,成倍减少相同数据率下的发射脉冲数量;同时采用差分编码的方式,降低了调制解调对晶振和PLL提供的高精度时钟的需求,适用于体积受限的无晶振场景。
基于多相环路振荡器的数字边沿组合发射机架构,通过高效率的脉冲生成模块,脉冲整形模块和PA模块,实现了所提出的混合调制方式。基于该架构的40nm发射机,在达到
1.8Gbps的吞吐率的同时,功耗仅4.09mW,能量效率达到了2.3pJ/bit,实现了相关工作中最高的传输速度和最优的能量效率,也是首个高速无晶振的IR-UWB发射机。最后,这一发射机在体外经皮传输实验中实现了20cm的经皮传输距离。
该工作面向超高速串行传输应用,针对传统判决反馈均衡器时序难以满足、前馈均衡器采样保持功耗较大的问题,设计并实现了一款
超高速接收机前馈均衡器芯片,传输速率、均衡能力与能效比均为同类芯片最优水平。北京大学盖伟新-何燕冬教授团队提出了基于延迟线与分布式抽头的前馈均衡技术:该技术利用无源延迟线在超高速场景下损耗小的天然优势,解决了对模拟信号延时的功耗与噪声较大的问题,在实现
200Gb/s超高速率均衡的同时,利用分布式结构降低了抽头负载电容引入的信号反射;此外,通过在抽头放大器中采用源极RC退化技术,赋予前馈均衡器灵活的低频均衡能力,避免仅靠增加抽头数量来消除长尾码间干扰,大幅降低了电路功耗。基于上述创新技术,课题组研制了一款
基于延迟线Gb/s接收机前馈均衡器芯片。该芯片实现了对200Gb/s数据的均衡,可提供高达17.2dB
的均衡能力,且能效比仅0.43pJ/b,均为接收机连续时间前馈均衡器的最优水平。
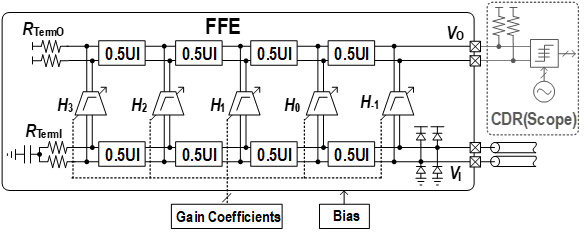
该均衡器芯片具有高带宽、低功耗、低噪声的优势,可广泛用于数据中心、Chiplet等串行数据传输应用中,为未来短距200Gb/s接收机提供了全新的低功耗解决方案。

,通过槽线变压器结构为推-推式二倍频器(push-push frequency doubler)在超宽带范围内实现了高平衡度的基波输入和最佳二次谐波调谐,有效地提高了倍频器的工作带宽、输出功率和基波抑制水平。▲宽带太赫兹倍频芯片(图源:清华大学电子工程系)
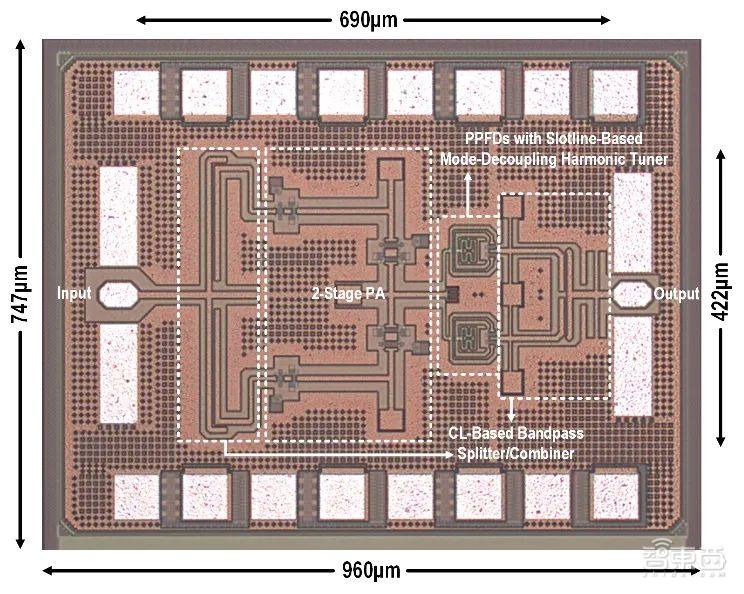
基于0.13μm SiGe BiCMOS工艺成功流片,在200至350GHz频带内实现了最高4.7dBm的输出功率和最大37dBc基波抑制水平,功率波动仅为3.6dB,其各项性能指标在超宽带范围内达到甚至超过了相似频段的窄带太赫兹倍频芯片。▲宽带太赫兹倍频芯片指标(图源:清华大学电子工程系)